One problem I’ve encountered during fuzzing is how to best fuzz an application that performs multiple file reads on an input file, but in a performant way (e.g. in-memory without actually touching disk). For example, say an application takes in an input file path from a user and parses it, if the application loads the entire file into a single buffer to parse, this is simple to fuzz in-memory (we can modify the buffer in-memory and resume), however if the target does multiple reads on a file from disk, how can we fuzz performantly?
Of course if we’re fuzzing by replacing the file on disk for each fuzz case we can fuzz such a target, but for performance if we’re fuzzing entirely in-memory (or using a snapshot-fuzzer that doesn’t support disk-based I/O) we need to ensure each read operation the target performs on our input does not actually touch disk, but instead reads from memory.
The method I decided to implement for my fuzzing was to hook the different file IO operations (e.g. ReadFile) and implement my own custom handlers for these functions that redirects the read operations to memory instead of disk, this has multiple benefits:
- We eliminate syscalls, as lots of file operations result in syscalls and my custom handler does not use syscalls, we avoid context switching into the kernel and obtain better perf
- We keep track of different file operations but it all operates on a memory-mapped version of our input file, this means we can mutate the entire mem-mapped file once and guarantee all
ReadFilecalls will be on our mutated Memory-mapped file
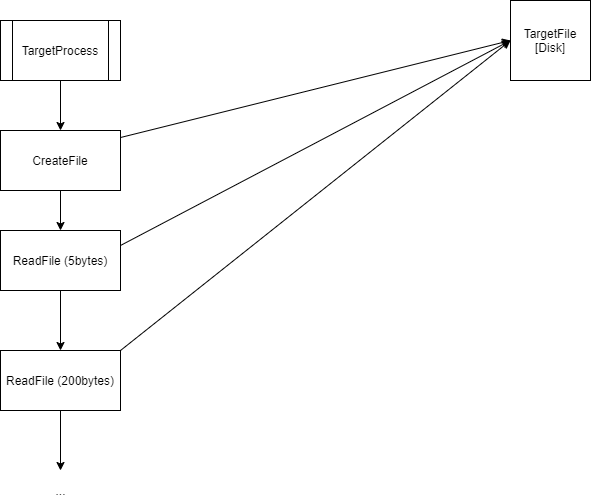
The normal operation of reading a file (without using my hooks) is:
CreateFileis called on a file targetReadFileis used on the target to read into a buffer (resulting in syscalls and disk IO)- Process parses the buffer
ReadFileis used on the target to read more from the file on disk- Process continues to parse the buffer
With our hooks, the operations instead look like:
CreateFileis called on a file target (our hook memory maps the target once entirely in-memory)ReadFileis used on the target to read into a buffer (resulting in our customReadFileimplementation to be called via our hook, and we handle theReadFileby returning contents from our in-memory copy of the file, resulting in no syscalls or Disk IO)- Process parses the buffer
ReadFileis used on the target to read more from the file (in-memory again, just like the firstReadFile)- Process continues to parse the buffer
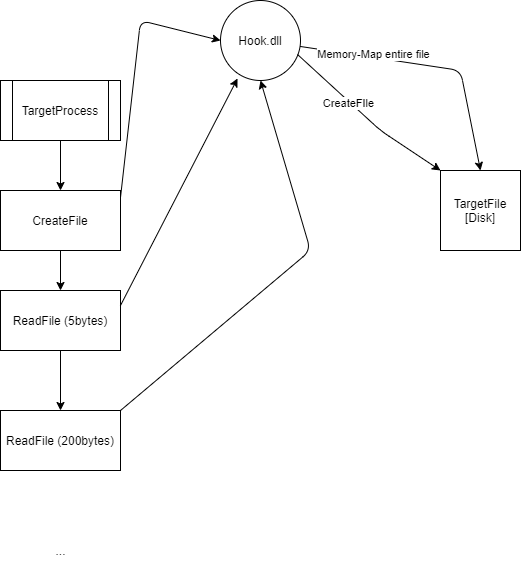
This greatly simplifies mutation and eliminates syscalls for the file IO operations.
The implementation wasn’t complex, MSDN has good documentation on how the APIs perform so we can emulate them, alongside writing a test suite to verify our emulation accuracy.
The code for this can be found on my GitHub: https://github.com/Kharos102/FileHook